-
on implicit filter level sparsity in convolutional neural networks카테고리 없음 2019. 10. 22. 20:45
본 논문은 엄밀한 사유보다는, 실험에 의한 관찰을 정리했다.
그래도 본 논문에서 건질 수 있는 몇 가지 내용만 요약하자면..
- L2 Norm와 Weight Decay는 서로 다르다
- 정규화가 없이는 sparsity가 관찰되지 않는다
- adaptive optimizer(Adam, Adagrad, Adadelta)에서 SGD보다 sparsity가 커진다
- Sparsity는 L2 Norm > Weight Decay
- 문제가 어려워질수록(논문예시: CIFAR10 -> CIFAR100) sparsity 감소
- Sparsity 뿐만 아니라 Selectivity-Universality를 같이 봐야함
=> Selectivity 가 크면 특정 상황에서만 활용되고, Universality가 크면 전체적으로 활용됨
Figure1에서 보면, SGD보다 Adam과 같은 optimizer에서 sparsity가 크게 나타남. L2와 WD를 비교해보면 L2에서 sparsity가 더 크고, 성능도 L2에서 더 좋게 나타난다.

Figure1
Layer별로 sparsity를 보면 가운데 쪽이 작고 Input과 Output쪽에서 sparsity가 크게 나타난다. 아래 결과를 추가적으로 이해해보자면, 일반적인 모형을 설계할 때 가운데 Layer의 노드를 더 크게 해주는게 좋을 것 같다는 생각이 든다.
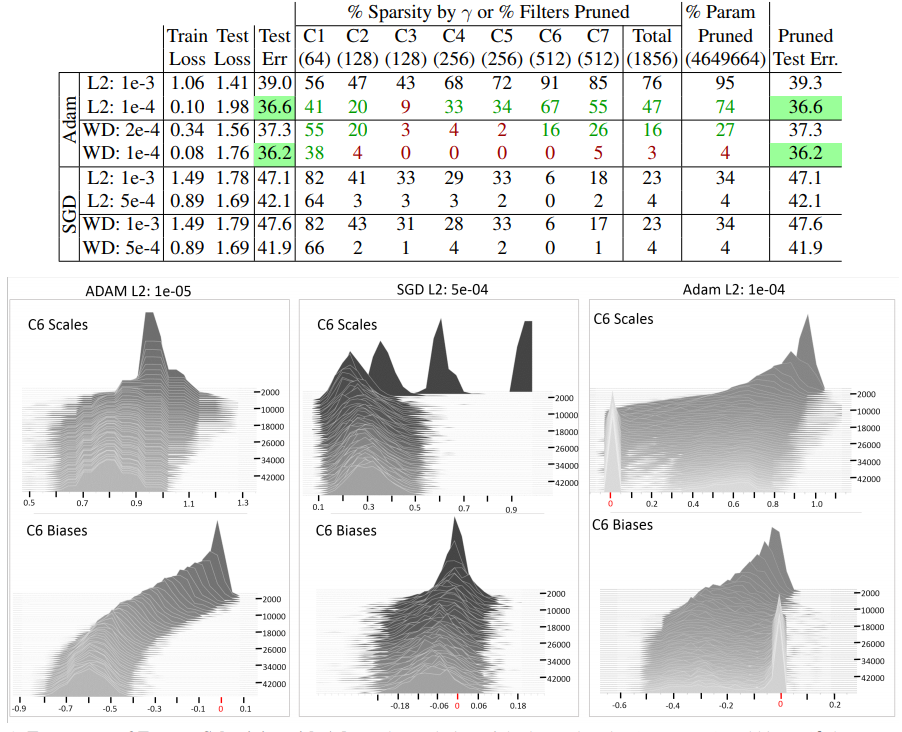
Figure2
Figure3에서 x축은 universality이고, y축은 해당 구간의 histogram이다. Adam에서 universality가 더 낮게 나타나며, 더 깊은쪽의 layer에서 selectivity가 크게 나타나는 경향이 관측된다.

Figure3